
Online Adaptive Anomaly Detection for Augmented Network Flows
Online Adaptive Anomaly Detection for Augmented Network Flows
论文链接:https://ieeexplore.ieee.org/document/7033682
Abstract
在本文中,我们提出了一种用于增强流的动态异常检测方法。我们在流创建期间绘制网络状态的草图,以实现通用威胁检测。我们设计和开发了一种基于支持向量机的自适应异常检测和关联机制,该机制能够在没有先验警报分类和在线进化模型的情况下聚合警报。我们开发了一种置信转发机制,用于识别用于额外处理的一小部分预测。我们展示了我们的方法在企业和主干轨迹上的有效性。实验结果表明,该算法能够在不需要离线训练的情况下保持高精度。
关键字:基于流的异常检测,在线自适应,支持向量机,动态输入标准化
Introduction
在本文中,我们提出并开发了一个自主数据收集和异常检测系统,以实现以下目标:
(1)判断流记录,其信息能够区分各种异常类,适合用于高速网络,而不需要有效负载检查。
(2)实时在线识别异常。
(3)为操作员提供设置置信度阈值的能力,以便转发低置信度的预测,以最大化资源效率。
(4)在线适应,而不需要持续的离线再培训或校准。
(5)为聚合的警报提供可操作的信息,包括导致异常的特定流或流组。
基于计数草图的高效流增强方法,该方法提供并行于流记录生成的每个流、每个节点和每个网络级统计数据。多级流数据的添加使我们的检测引擎能够识别异常网络条件展开时,而不是在它们发生之后。
基于流的网络异常检测的在线自适应支持向量机(SVM)。我们的模型是基于一类SVM,由一个改进的序列最小优化算法求解。我们通过提出四个重大的改进来解决已确定的问题。
首先,我们通过维护一个基于在线反馈的辅助训练集来增强传统的增量SVM。该集基于操作员的反馈进行适应,使系统能够响应概念漂移,显著提高预测能力,同时保持足够有效的实时适应。
其次,我们使用动态输入归一化过程,监测输入连接的观测值的范围和方差,并在在线归一化过程中使用信息来适应输入和特征空间尺度。通过这种方法,我们动态地适应了最敏感的特征的影响,同时也降低了离群值的敏感度。
第三,我们提出并开发了一种新的方法来计算一类支持向量机的预测置信度,以识别基于内容遗忘异常的系统无法正确分类的流量模式。虽然传统的SVM置信方法使用接近超平面作为主要指标,但我们的方法识别了超平面中最和最不可能将异常与恶意意图正确关联的部分。
- 最后,我们开发了一种轻量级进化警报聚合方法,并将其与阻塞、过滤和转发机制的检测置信度相结合,从而直接减轻预测,并可以将低置信度过滤或转发连接进行进一步处理或评估,如服务质量(QoS)缓解、内容感知入侵检测或人工检查。
网络流量增强方法
工作流程和示例
在所提出的在线自适应异常检测框架中,当接收到流量时,首先将其归纳为增强的流向量。然后将其与相关的警报记录进行比较。如果找到了一个匹配项,则该流量将被阻塞。如果未找到匹配项,则由检测引擎对其进行评估。如果预测置信度较高(超过操作员定义的阈值),则根据预测来处理流量。如果置信度较低,则预测和相关的流量将被转发以进行附加处理。图1总结了这个过程。
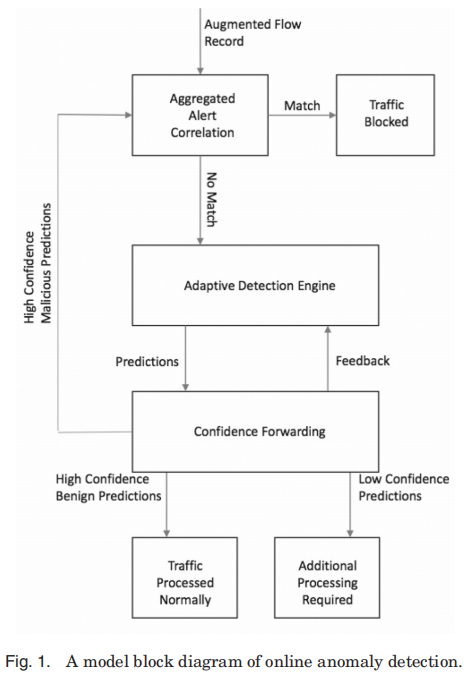
举例来说,考虑一个为用户添加了新的统一通信服务的企业网络。当该服务首次可用时,与正常流量相比,生成的流量可能被认为是完全异常的。通过图1中所示的图表,连接将被分组为流,并使用下一小节中所述的附加字段进行扩展。流信息将与现有的相关警报集进行比较,并且不会找到匹配项。未来的流量被正常处理,连接由自适应检测引擎评估连接。由新服务生成的流量与正常的流量模式基本异常,因此被高度自信地标记为恶意的。警报记录被生成并存储在警报相关引擎和操作员日志中。(新服务是异常的)
最初,支持新服务的流量将开始产生警报记录,从而导致流量被阻塞。然而,了解该新服务的网络运营商能够快速验证该流量是否是良性的,并将该警报记录标记为误报。该反馈由检测引擎处理,模型进行调整。从相关引擎中删除不必要的警报记录,数据规范化演变到新流量,新服务生成的未来流量被正常处理。(新服务误报被人工处理)
现在考虑一个正在进行DDoS攻击的例子。流量很容易被识别为异常的。同样,在 Alert Correlation Engine不过滤初始流量。但是,随着攻击的展开,警报记录将被添加到相关引擎中。假设恶意流量虽然来自许多源地址,但它共享少量的src端口(即端口0)。警报记录快速关联,并能够区分针对受害者网络节点的恶意流量和良性流量,因此只有恶意流量被阻止。
在另一个例子中,考虑一个攻击者使用恶意代码而被攻击的网络。攻击可能会产生网络异常,但检测引擎正在处理与检测置信度低的异常流量和足够的正常流量。与这些异常警报相匹配的预测将被转发,用于其他处理(如深度数据包检查)。
增强网络流记录
我们提出并开发了一种基于计数草图的高效流增强方法,该方法提供并行生成流记录的每个流、每个节点和每个流级统计数据。网络流是在一定时间间隔内通过观察点的IP数据包。属于一个特定流的所有数据包都有一组公共属性。在这项工作中,常见的属性是源和目标地址、源和目标端口号,以及IP协议: (src_addr, dst_addr, src_port, dst_port, protocol).
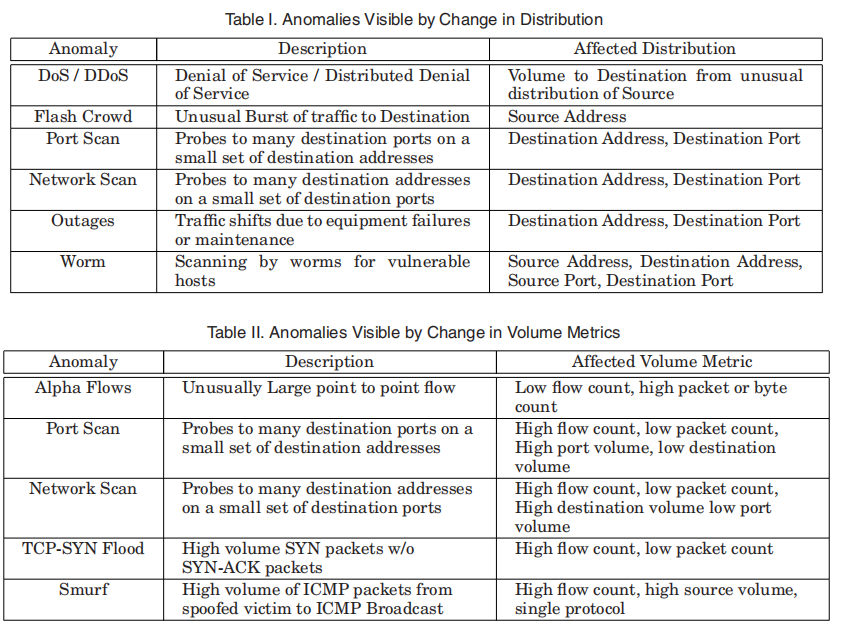
分析异常检测的流量数据通常包括监测特定的时间间隔,并在这些时间间隔内的流量记录数据场体积和流量记录数据场分布中寻找异常。通过此方法可以检测到几种类型的网络攻击/异常。表一和表二列出了几个基于分布(Distribution)和体积度量(Volume Metric)的可识别攻击的示例。
我们的目标是为检测器提供同时生成流量记录的网络范围信息,以减少检测延迟。我们还希望提供具有体积(Volume)和分布信息(Distribution)的组合的检测器,以便检测器可以通用化,而不是专门用于特定的攻击签名。最后,该采集方法必须具有计算效率,以支持在线/近实时检测,并且必须具有可伸缩性,以支持高速/主干链路。我们提出了一种基于流的数据收集方法,该方法使用统计计数方法,用额外的信息(用于推断与所考虑的流相关的整个网络的状态)来增加传统的流数据。该方法效率极高,增强了单流异常检测能力。它还允许网络范围内的异常检测,同时几乎实时地跟踪贡献流。
我们用一组附加信息来增加基本的流记录,这些信息直接提供了体积度量(Volume),但也允许检测器推断出特定字段中的分布信息(Distribution)。一个流是由一组五个关键元素来标识的 (src_addr, dst_addr, src_port, dst_port, protocol)。我们生成由这些元素的子集组成的流键。有31($2^{5}-1$)个可能的流键,即src_addr、dst_addr、src_port、dst_port、protocol等。我们选择所有至少包含src_addr或dst_addr的流键,并使用与这23个键相匹配的网络宽卷信息来扩充记录。请注意,有24个可能的键。但是,我们排除了包含整个五元组的键,因为这个键通常不会在一个时间窗口内聚合多个流,即,如果流窗口是60秒,那么在这60秒内匹配整个五元组的所有连接通常都是相同的流。
当生成一个流记录时,它将被增强,从而记录来自前w秒的流、数据包和字节计数,其中w是一个可配置的参数。很明显,使用这种方法可以直接向检测器获得体积信息。然而,这种方法也允许检测器推断出一些有限的一般连接分布信息。回想一下,流和连接之间存在着区别。如果涉及相同关键元素的多个连接出现在一个流的活动超时时间内,那么它们将被聚合成单个流记录。在活动超时窗口内发生的类似端口上的从单个源到多个目的地的多个连接将生成不同的流记录。包括键{src_addr},一个流记录将包括以前从同一源处理到所有目的地、所有端口和所有协议的流的总数。键{ {src_addr},{dst_addr} },它将包括在所有端口、所有协议等上从同一源到相同目的地的流的总数。通过结合所有23个密钥,可以实现对网络活动的不同层次分布的有限估计。为了有效地完成这个数据收集,我们使用了一组修改后的计分钟草图结构数组来管理流数据。
绘制网络流量统计信息
流级统计数据的计算,如大流的大小和标识、每个流量和流量大小分布,对于网络管理和安全至关重要。在高速链路上测量这些信息是具有挑战性的,因为保持精确的每流状态(例如,使用哈希表)来跟踪各种流统计的标准方法非常昂贵。随着添加更多的项,数据结构使用的内存量随着时间的推移会变得非常大。由于它的大小很大,访问这样的数据结构可能相当慢。此外,由于数据结构的大小会随着时间的推移而增加,因此需要周期性地调整数据结构的大小,因此不适合进行高速网络中的实时处理。我们通过使用计数分钟草图来估计流量统计数据来克服这些障碍。



