
字节编码和K-S检验新改进
本周主要进行了K-S检验,字节编码(结合nprint和ESBNN)的改造,有一些不成熟的有意思的结论和想法。
K-S检验
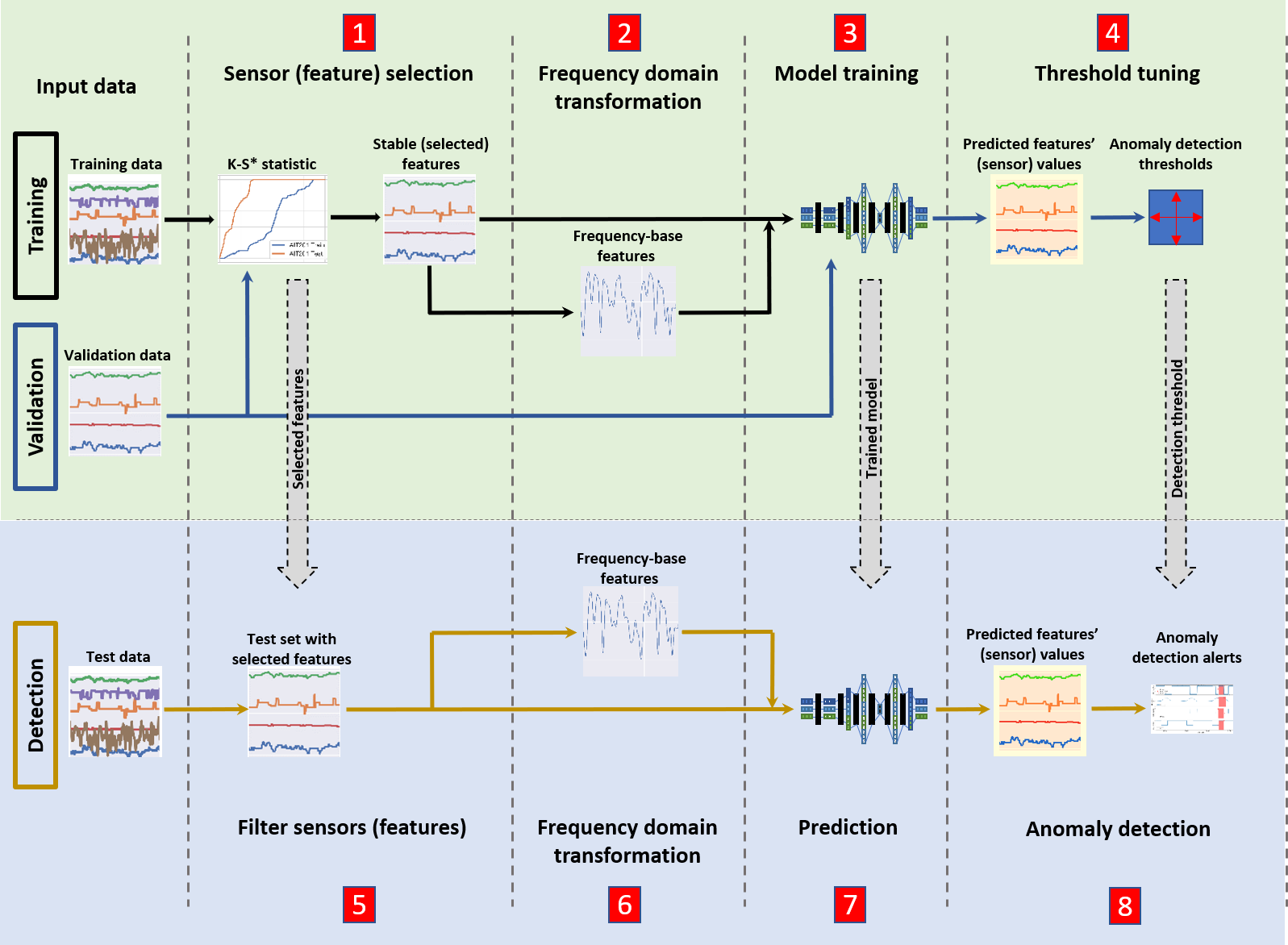
论文《Efficient Cyber Attack Detection in Industrial Control Systems Using Lightweight Neural Networks and PCA》的基本思路是将sensor收集到的feature经过K-S*检验,stable feature经过DFFT基于频域提取频域特征和unstable feature一起进行模型训练。
模型结构如下图:
因此K-S检验是必要的第一步,K-S检验是用来检验两组样本的数学分布。
参考:K-S检验的数学理解在:K-S检验数学理解
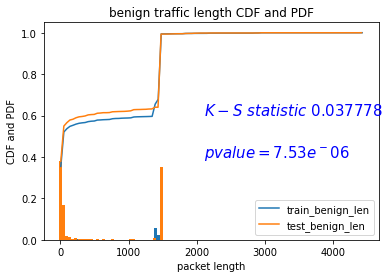
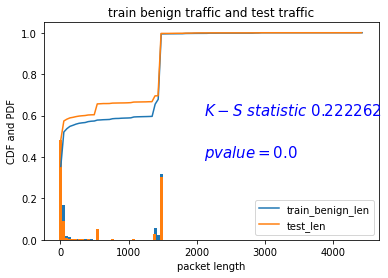
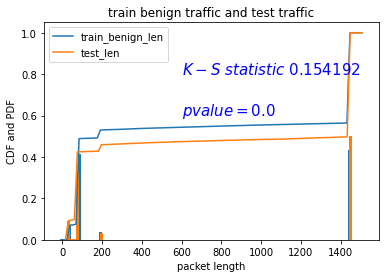
在mawilab 10w数据集中对IPv4 header:len这个属性进行K-S检验。用K-S检验测试训练集9w条和测试集合1w条。使用了python中的scipy.stats的ks_2samp函数。
下面是CDF和PDF图,左边的图片是使用了train data和test data中的良性流量集合;右边的图片是使用了train data中的良性流量集合和test data(好坏流量都有)。结论是K-S statistic明显翻倍了很多,意味着良性流量和恶性流量包在len这个属性上的分布是不一样的。
进一步实验验证:
换数据集:ids2017 里面的SSL_Regression 20w
train data:18w test data:2w
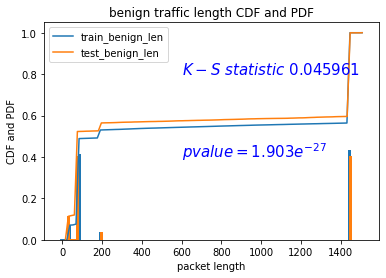
换特征:IPv4 header:proto

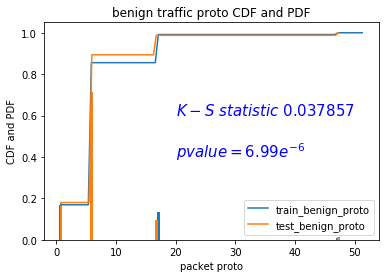
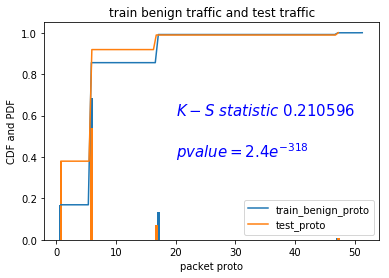
但是我这样的验证,还是不能很有力的说明我的结论。接下来,我先说一下我的字节编码改造思路,在最后的思考中提出应该如何大规模的验证这个结论,并且给予应用。
改造字节编码
结合《EBSNN: Extended Byte Segment Neural Network for Network Traffic Classification》和《nprint》的思路。
EBSNN: Extended Byte Segment Neural Network for Network Traffic Classification
参考链接:关于EBSNN的拓展字节编码方式具体细节可以看Byte Segment Neural Network for Network Traffic )方便理解。
EBSNN提出了过拟合的概念,字节编码是用了前64个字节,这64个字节中会包含下图的一些属性,这些属性在EBSNN中被放弃了,看到这里我也疑惑不解,于是我进行了实验验证。

举个例子,ESBNN是这么处理raw data的。

于是,我在textCNN代码的基础上,放弃了Ethernrt II header和IPV4 header,python代码如下:
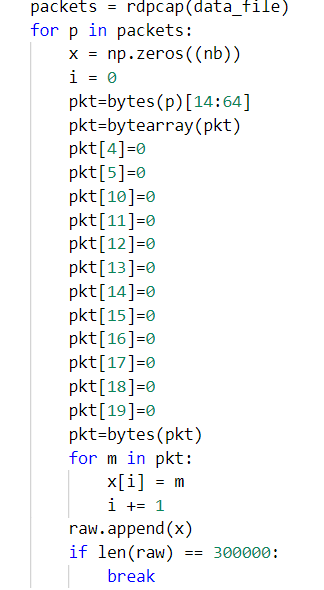
结果:
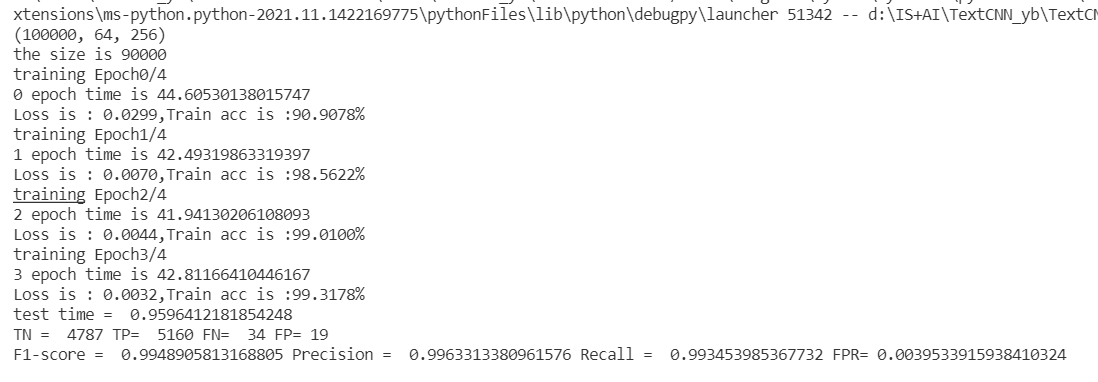
可以验证放弃某些字段并不影响F1值。
nprint的方法是:

思考
我所思考的新的字节编码方法是:
- 在nprint基础上,在新字节编码中放弃一些ECBNN中提到的过拟合的字节;
- 在ESBNN基础上,添加ICMP的features;
- 关于对抗攻击,我的想法是既然保留了物理意义,不妨就进行PSO替换的算法,模仿之前的TrafficManipulator进行实际字节的替换。可以写一个配置文件,自主选择替换哪些有物理意义的字节。
- 关于FGPM,它其实可以理解成一种优化方法,根据投影加快单词替换速度的,进而加快对抗攻击的速度。可加可不加。
- 在K-S检验的基础上,我们可以添加一个自动特征选择模块,依据stastic值,过滤掉某些和训练集分布相同(stastic值很小的)的特征,再进行训练。这样会提高训练效率。
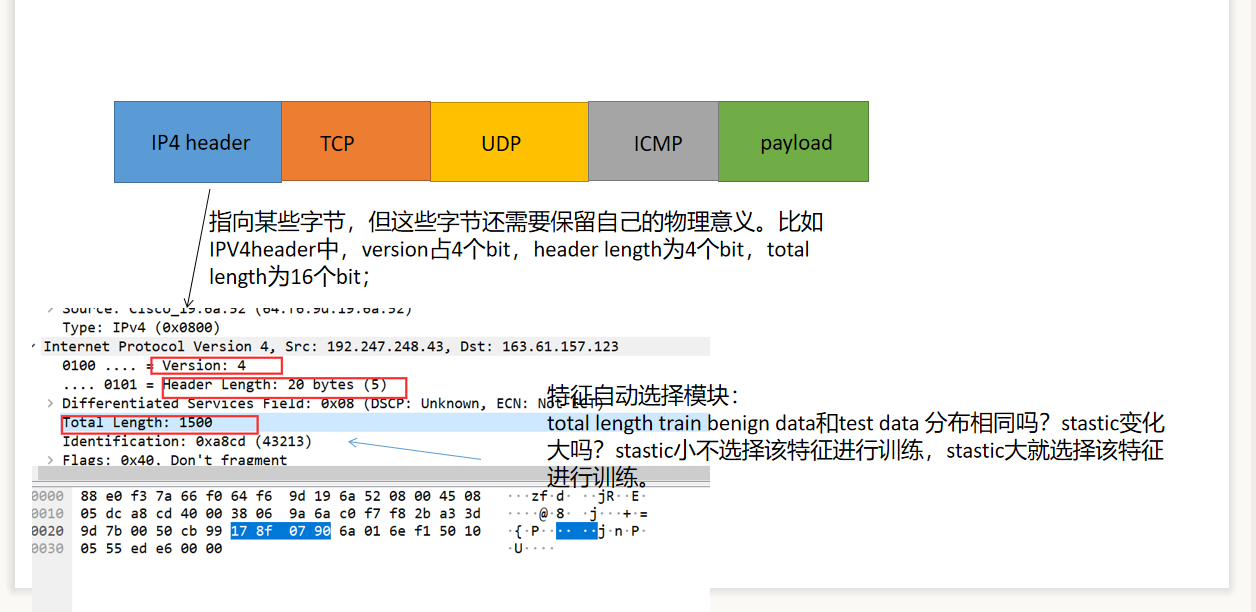
还有些没考虑到的问题:
- 我不知道packet level 该怎么给字节编码加时间序列
- 有没有必要添加自动特征选择模块以提高精度和训练效率



