
关于文本对抗攻击FGPM的思考
关于文本对抗攻击FGPM的思考
《基于同义词替换的快速梯度映射(FGPM)文本对抗攻击方法》阅读笔记

《Adversarial Training with Fast Gradient Projection Method against Synonym Substitution based Text Attacks》
论文链接:https://arxiv.org/pdf/2008.03709.pdfarxiv.org/pdf/2008.03709.pdf
对抗攻击在提升模型鲁棒性方面获得了巨大成功。然而,对于文本任务而言,基于同义词替换的对抗攻击方法有用但效率不高;而效率较高的基于梯度(Gradient-based)的对抗方法,在样本空间连续的图像领域应用广泛,但受限于文本的离散特性以及语法、语义的约束,很难直接应用于生成对抗样本(这里指生成具体的样本)。本文提出了基于同义词替换的Fast Gradient Projection Method(FGPM)方法,在提升效率的同时能保持同等的对抗性能。
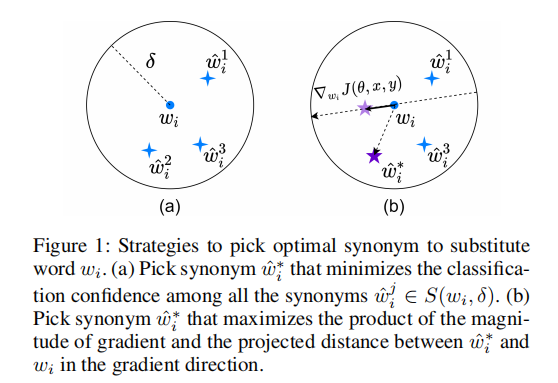
此前的基于同义词替换的对抗攻击方法,往往是选择$w_{i}$在词向量空间邻域$\delta$内的所有词作为同义词候选集,随后逐一使用同义词$\{\hat{\omega}_{i}^{j} \}_{j=1}^{n}$替换原始 $w_{i}$,送入模型forward,最后选择使得Ground Truth类别概率最低的同义词作为最终替换词。这种方法需要多次做forward,因此效率很低。
本文提出的方法如上图(b)所示,基于Fast Gradient Value (FGV):
首先使用原始句子做一次forward,得到损失$J( \theta ,x,y)$;
随后模型backward,可以获得损失函数针对每个词向量的梯度$ \nabla_{w_ {i}} J( \theta ,x,y)$ ;
对于每个词 $ w_ {i} $ ,计算其同义词集 $S( w_ {i} , \delta) $ 中每个词词向量与$ w_ {i} $词向量之差在上述梯度下的投影的长度,然后选取投影长度最长的那个词作为目标同义词:
上述过程决定了每个词级别的同义词选取;对于每句话,同样优先选取投影长度较长的样本做同义词替换;
为了避免整体句意偏移,将最大替换概率设置为0.25,同时只选取一定范围内的同义词$|| \hat{\omega}_{i} - w_ {i} ||_ {2} < \delta , \delta =0.5$。
最后,模型的训练目标为:
这里加入的第三项作者称为Logit Pairing,目标是使得原始样本和对抗攻击样本经过模型后,生成的类别logits尽可能相近。实验中,$\alpha$ 和 $\lambda$ 均取0.5。
实验显示,本文提出的方法在对抗攻击(使模型性能下降)、增强模型鲁棒性(使用对抗生成的样本辅助训练)上,均取得了不错效果。
传统的方法是在一定范围内的文本空间内搜索,而FPGM这种基于梯度的方法利用投影的方法巧妙的加快了训练的效率。
探究文本对抗攻击FGPM在特征空间上能否用于恶意流量检测的攻击
任务前言:
基于字节编码的方法,使用TextCNN模型训练,在packet-level上实现恶意流量包的分类。针对以上所述的问题,我在猜想能否通过FGPM的攻击的方法,实现字节的替换,从而降低分类准确率。
代码结构:
textcnn.py,textrnn.py,textbirnn.py: The models for CNN, LSTM and Bi-LSTM.train.py: Normally or adversarially training models.utils.py: Helper functions for building dictionaries, loading data, or processing embedding matrix etc.build_embeddings.py: Generating the dictionary, embedding matrix and distance matrix.FGPM.py: Fast Grandient Projection Method.attack.py: Attack models with FGPM.Config.py: Settings of datasets, models and attacks.
在GPU上跑这份代码的时候,仔细研究了内部结构,觉得实现不太可行。有这样的一些原因:
首先,它是针对一个多分类问题,恶意流量监测是二分类的问题;第二,它是只针对文本分类,泛用性不强;第三,替换的最小单元是词,他要求生成一个词库,还需要停用词等很多中间数据,我们现有的字节编码方法并不适合;最后,实现难度较大,工程量很大,且运行速度不如FGSM快。
最主要的问题是FPGM的初衷是不改变句子原意的基础上改变分类器的结果,它是对一个句子(句子的长度大小内容不定)中的某些单词进行替换的,而我们分析流量包是通过字节编码的方式的,如果我们以字节为单位形成一个词库,这些词库里的字节,它的某些单位(例如mac地址、ip地址形成的字节)是没有意义的。其实,工程量很大才是最主要的原因😅,我没有必要浪费这个时间去做这个对目前的研究帮助不大的事情😕。
New idea
我们需要寻找到一种方法进行某个特定单位间的替换,每个特定的字节位置及意义要匹配,或许可以在FGPM的基础上改进???我觉得这个idea可以试一试??如果我能够结合nprint,将包的种类进行一个分类,根据不同分类分割字节,这样就有了可解释性。再通过FGPM进行攻击?
具体操作步骤:
1.参考nprint对流量包的分类方式,在这个分类上划分字节,把字节视作单词,录入词库。
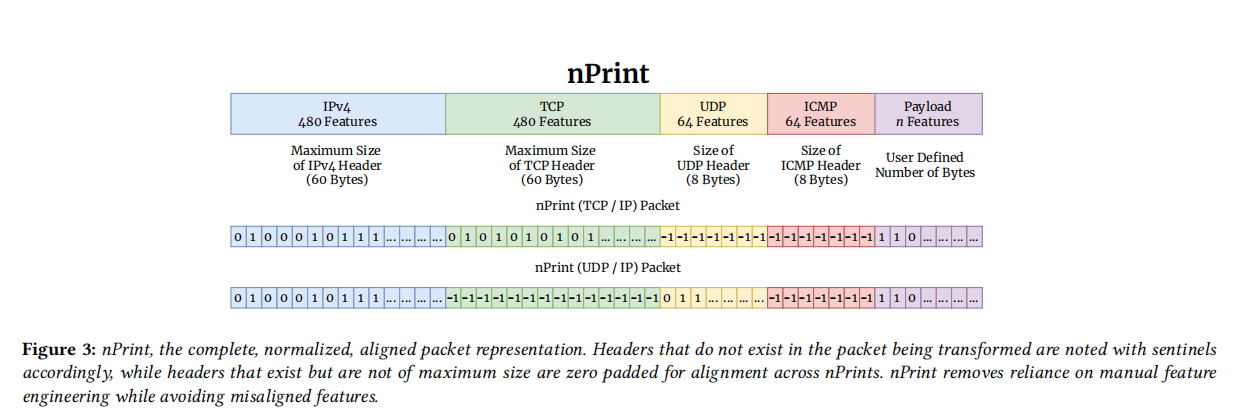
2.FPGM攻击



